Qu’est-ce que le Data Vault, et quand faut-il s’en servir ?

Evan Pearce
Le Data Vault 2.0 intègre une technique de modélisation et peut servir de cadre méthodologique à tous les projets d’entrepôt de données.
Depuis de nombreuses années, les projets d’informatique décisionnelle fonctionnent avec une approche en cascade. En fait, ils s’articulent en une longue séquence d’étapes, chacune associée à un grand nombre d’exigences préalables, le tout reposant sur un modèle de données et encadré par un ensemble de règles métier de contrainte et de dérivation codifiées dans un processus d’extraction, de transformation et de chargement des données (ETC). La couche de visualisation est construite de manière séquentielle avant d’être présentée à l’utilisateur final pour validation, parfois des mois, voire des années après le début du projet.
Souvent, les équipes fragmentent le projet initial en plusieurs petits projets. Cette démarche réduit la complexité, mais présente deux risques majeurs :
- Le cahier des charges évolue plus vite que la capacité à livrer.
- Les responsables des budgets ne veulent pas investir dans un projet à long terme qui ne produit rien à court terme.
Ces deux raisons expliquent pourquoi la méthode agile, itérative et flexible, a supplanté la méthode en cascade dans la gestion de projet. Elle se base sur une reconnaissance de ces problèmes et y apporte des solutions.
Dans le domaine de l’analyse de données, en revanche, la méthode agile seule ne répond pas aux difficultés plus subtiles de l’entreposage de données et des projets d’informatique décisionnelle. Notamment :
- L’itération dans la modélisation de données.
- La réduction du réusinage.
- L’élaboration de processus d’ETC qui permettent une adaptation rapide à l’évolution des besoins ou à l’ajout de données.
- La mise en place d’une approche de collecte des besoins qui s’articule finement avec le processus de prise de décision conceptuelle.
Pour répondre à ces difficultés, Daniel Linstedt, auteur de Building Scalable Data Warehouse with Data Vault 2.0, a combiné les forces de l’organisation agile et celles d’autres disciplines et techniques efficaces dans une méthodologie qui constitue probablement l’approche la plus itérative de l’informatique décisionnelle jamais définie.
Qu’est-ce que le Data Vault?
Contrairement aux idées reçues, le Data Vault (DV)* n’est pas qu’une technique de modélisation : c’est une méthodologie complète de gestion d’entrepôt de données. Elle associe méthode agile, approche BEAM de collecte des besoins, modèle CMMI, gestion intégrale de la qualité (GIQ), approche six sigma et modélisation Data Vault pour définir une approche qui vise à accélérer les projets d’informatique décisionnelle et à en améliorer la qualité. J’appelle ça l’« approche du missile à tête chercheuse », car elle est à la fois précise et flexible.
Le DV puise également dans la méthode agile pour estimer des tâches propres aux projets d’entrepôt de données afin de déterminer la complexité ou la charge de travail, souvent ignorées, qu’impliquent les composantes habituelles d’un tel projet. À une échelle plus fine, le DV propose une approche itérative et particulièrement concise de production de livrables techniques essentiels (dans le monde de l’informatique décisionnelle) associés à des fonctionnalités nouvelles ou modifiées. Cette approche joue notamment sur des processus agiles rigoureux, répétables et itératifs pour exécuter des tâches qui reviennent souvent, par exemple l’ajout d’attributs, de coupes de données, de nouvelles sources, de données provenant de sources existantes, d’historiques, de sources abandonnées et de changements de structure de sources pendant les phases d’ETC et de modélisation.
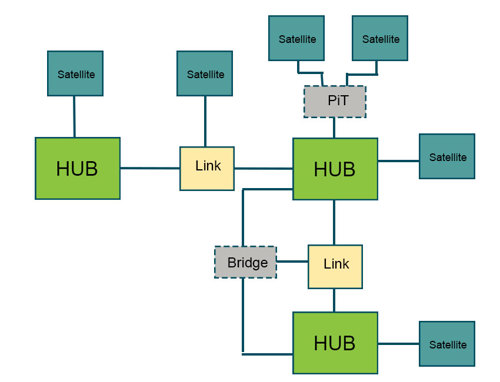
Pour faire simple, le DV est une couche superposée entre la modélisation dimensionnelle classique (traitement analytique en ligne ou OLAP, schéma en étoile) et l’activation de données qui facilite l’adaptation aux besoins opérationnels grandissants et dénoue la complexité de la modélisation et du processus d’ETC. Ce modèle est composé de hub neuronaux (entités métier), de links (relations) et de satellites (attributs descriptifs) modélisés selon une approche située quelque part entre la troisième forme normale (3NF) et le schéma en étoile. Il est positionné dans la couche d’intégration de l’entrepôt de données, souvent nommée le Raw Data Vault, et utilisé en combinaison avec le modèle de Kimball.
Astuce : Si vous voulez en savoir plus sur le modèle et son fonctionnement, je vous recommande le livre de Daniel Linstedt mentionné ci-dessus.
*Veuillez noter que ceci réfère à un texte disponible en anglais seulement.
Les avantages du Data Vault 2.0
Voici une liste des grands avantages de l’approche Data Vault 2.0 :
- Conception adaptée aux relations de modélisation les plus complexes. Link N:M entre les objets métier pour éliminer le besoin d’une mise à jour lorsqu’un link 1:M devient un link M:M, et donc tout travail sur la structure lorsqu’un link change de degré.
- Modèle conçu pour enregistrer un historique continu de tous les aspects des données, notamment les relations et les attributs, et de leurs sources. Les satellites, qui fonctionnent sur le même principe que les dimensions, se comportent de la même manière que les dimensions à évolution lente (SCD) de type 2.
- Ensemble de principes de conception et de structures qui améliorent la performance de suivi historique dans le Vault (PiT et Bridge). Suffisamment flexible pour adopter ces structures à tout moment dans le processus itératif de modélisation, sans planification complexe.
- Sépare logiquement les espaces contenant respectivement des données brutes et altérées. Le Raw Data Vault sert de bases aux données auditables à partir de leur système source, et le Business Vault sert d’espace aux utilisateurs qui ont besoin de données à un niveau inférieur du minientrepôt en contexte opérationnel.
- Séparation des règles métier de contrainte et de dérivation en différentes composantes de l’intégration de données. Cette méthode permet la réutilisation des données au fil des requêtes. Par exemple, les données brutes ne sont appelées qu’une fois dans le Data Vault (moins de réintégration pour l’activation) et peuvent être mobilisées plusieurs fois selon les besoins en aval.
- Le Data Vault, qui stocke l’historique de toutes les données, est facilement extensible à chaque itération, sans risque de perdre ces données d’historique. D’ailleurs, les données historiques sont stockées indépendamment du modèle dimensionnel.
- Fonctionne par condensation des clés métier en valeurs hachées, ce qui réduit le temps d’interrogation et accélère le chargement parallèle. En somme, le chargement séquentiel nécessite moins de dépendances.
- Le Raw Data Vault est conçu de manière à être complètement auditable.
- Traitement des données plus fluide et itératif entre l’activation de données d’une part, et le schéma en étoile et l’OLAP d’autre part.
- Approche rigoureuse de combinaison de données avec différentes clés métier à partir de sources hétérogènes (un problème d’intégration fréquent dans les entrepôts de données avec plusieurs systèmes sources). Les clés métier ne sont pas toujours en relation 1:1 ni toutes dans le même format.
- Le principe de modélisation « juste à temps » colle parfaitement avec l’approche agile.
Les désavantages
Si le Data Vault présente de nombreux avantages, il vient aussi avec des inconvénients :
- En essence, le Data Vault est une couche entre le minientrepôt de données/le schéma en étoile et l’activation. Concevoir cette couche demande des efforts de développement supplémentaires en matière d’ETC et de modélisation. Si le projet est de faible envergure ou d’une courte durée de vie, le modèle ne sera peut-être pas profitable.
- L’un des principaux intérêts du Data Vault est la facilité d’audit et de suivi historique. Si aucun de ces deux éléments n’a d’importance pour vous ou pour votre organisation, les efforts supplémentaires qu’implique le Data Vault peuvent être difficiles à justifier. En revanche, l’investissement peut être intéressant à long terme.
- Le modèle repose sur une approche décomposée des relations, des clés métier et des attributs, ce qui se traduit par la création de nombreux tableaux par rapport à une structure dénormalisée comme le schéma en étoile. Partez toutefois du principe que le Data Vault est complémentaire au schéma en étoile, donc la comparaison ne sert qu’à contraster les deux. Comme beaucoup de tableaux sont créés, visionner des données dans le DV nécessite beaucoup de jointures.
- À ce jour, peu de ressources existent sur le DV. Nous en savons peu sur les projets complexes qui y font appel.
- Cette approche peut être déstabilisante pour les personnes qui ont l’habitude du modèle de Kimball ou, dans une moindre mesure, d’Inmon.
Devriez-vous adopter le Data Vault?
La réponse dépend de plusieurs facteurs.
À notre opinion, le Data Vault est une approche parfaitement viable pour répondre aux besoins des projets d’entrepôt de données, où le suivi historique et l’audit des données sont des éléments cruciaux.
En outre, si les relations entre vos entités métier évoluent constamment (par exemple, de 1:M à M:M), le Data Vault simplifie leur modélisation et vous permet ainsi de vous concentrer sur la production de valeur concrète.
Si votre organisation souhaite stocker des renseignements personnels dans l’entrepôt de données, et qu’elle est assujettie au RGPD, au HIPPA ou à d’autres règlements, le Data Vault lui facilitera l’audit et le suivi historique des données.
En somme, il est important de peser le pour et le contre et de prendre une décision adaptée à votre contexte.
VOUS AVEZ UN PROJET ?
